Gradient
This article includes a list of references, but its sources remain unclear because it has insufficient inline citations. (January 2018) (Learn how and when to remove this template message) |

In mathematics, the gradient is a multi-variable generalization of the derivative. While a derivative can be defined on functions of a single variable, for functions of several variables, the gradient takes its place. The gradient is a vector-valued function, as opposed to a derivative, which is scalar-valued.
Like the derivative, the gradient represents the slope of the tangent of the graph of the function. More precisely, the gradient points in the direction of the greatest rate of increase of the function, and its magnitude is the slope of the graph in that direction. The components of the gradient in coordinates are the coefficients of the variables in the equation of the tangent space to the graph. This characterizing property of the gradient allows it to be defined independently of a choice of coordinate system, as a vector field whose components in a coordinate system will transform when going from one coordinate system to another.
The Jacobian is the generalization of the gradient for vector-valued functions of several variables and differentiable maps between Euclidean spaces or, more generally, manifolds. A further generalization for a function between Banach spaces is the Fréchet derivative.
Contents
Motivation[edit]
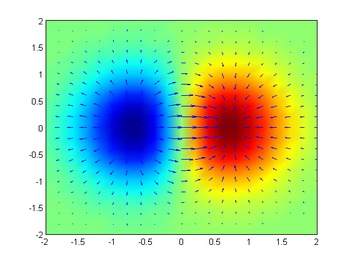
Consider a room in which the temperature is given by a scalar field, T, so at each point (x, y, z) the temperature is T(x, y, z). (Assume that the temperature does not change over time.) At each point in the room, the gradient of T at that point will show the direction in which the temperature rises most quickly. The magnitude of the gradient will determine how fast the temperature rises in that direction.
Consider a surface whose height above sea level at point (x, y) is H(x, y). The gradient of H at a point is a vector pointing in the direction of the steepest slope or grade at that point. The steepness of the slope at that point is given by the magnitude of the gradient vector.
The gradient can also be used to measure how a scalar field changes in other directions, rather than just the direction of greatest change, by taking a dot product. Suppose that the steepest slope on a hill is 40%. If a road goes directly up the hill, then the steepest slope on the road will also be 40%. If, instead, the road goes around the hill at an angle, then it will have a shallower slope. For example, if the angle between the road and the uphill direction, projected onto the horizontal plane, is 60°, then the steepest slope along the road will be 20%, which is 40% times the cosine of 60°.
This observation can be mathematically stated as follows. If the hill height function H is differentiable, then the gradient of H dotted with a unit vector gives the slope of the hill in the direction of the vector. More precisely, when H is differentiable, the dot product of the gradient of H with a given unit vector is equal to the directional derivative of H in the direction of that unit vector.
Definition[edit]

The gradient (or gradient vector field) of a scalar function f(x1, x2, x3, ..., xn) is denoted ∇f or ∇→f where ∇ (the nabla symbol) denotes the vector differential operator, del. The notation grad f is also commonly used for the gradient. The gradient of f is defined as the unique vector field whose dot product with any unit vector v at each point x is the directional derivative of f along v. That is,

When a function also depends on a parameter such as time, the gradient often refers simply to the vector of its spatial derivatives only (see Spatial gradient).
Cartesian coordinates[edit]
In the three-dimensional Cartesian coordinate system with a Euclidean metric, the gradient, if it exists, is given by:

where i, j, k are the standard unit vectors in the directions of the x, y and z coordinates, respectively. For example, the gradient of the function

is

In some applications it is customary to represent the gradient as a row vector or column vector of its components in a rectangular coordinate system.
Cylindrical and spherical coordinates[edit]
In cylindrical coordinates with a Euclidean metric, the gradient is given by:[1]

where ρ is the axial distance, φ is the azimuthal or azimuth angle, z is the axial coordinate, and eρ, eφ and ez are unit vectors pointing along the coordinate directions.
In spherical coordinates, the gradient is given by:[1]

where r is the radial distance, φ is the azimuthal angle and θ is the polar angle, and er, eθ and eφ are again local unit vectors pointing in the coordinate directions (i.e. the normalized covariant basis).
For the gradient in other orthogonal coordinate systems, see Orthogonal coordinates (Differential operators in three dimensions).
General coordinates[edit]
Using Einstein notation we can consider the gradient in general coordinates, which we write as x1, ..., xi, ..., xn, where n is the number of dimensions of the domain. Here, the upper index refers to the number of the coordinate or component, so x2 refers to the second component, and not the quantity x squared. The index variable i is used to refer to an arbitrary element, such as xi. The gradient can then be written as:

where and refer to the unnormalized local contravariant and covariant bases respectively, is the inverse metric tensor, and the Einstein summation convention implies summation over i and j. In terms of the normalized bases, which we refer to as and , using the identities and , where g is the determinant of the metric tensor. We can write:








which will evaluate to the expressions given above for cylindrical and spherical coordinates.
Gradient and the derivative or differential[edit]
| Part of a series of articles about | ||||||
| Calculus | ||||||
|---|---|---|---|---|---|---|
|
||||||
|
||||||
|
Specialized |
||||||
Linear approximation to a function[edit]
The gradient of a function f from the Euclidean space Rn to R at any particular point x0 in Rn characterizes the best linear approximation to f at x0. The approximation is as follows:

for x close to x0, where (∇f )x0 is the gradient of f computed at x0, and the dot denotes the dot product on Rn. This equation is equivalent to the first two terms in the multivariable Taylor series expansion of f at x0.
Differential or (exterior) derivative[edit]
The best linear approximation to a differentiable function

at a point x in Rn is a linear map from Rn to R which is often denoted by dfx or Df(x) and called the differential or (total) derivative of f at x. The gradient is therefore related to the differential by the formula

for any v ∈ Rn. The function df, which maps x to dfx, is called the differential or exterior derivative of f and is an example of a differential 1-form.
If Rn is viewed as the space of (dimension n) column vectors (of real numbers), then one can regard df as the row vector with components

so that dfx(v) is given by matrix multiplication. Assuming the standard Euclidean metric on Rn, the gradient is then the corresponding column vector, i.e.,

Gradient as a derivative[edit]
Let U be an open set in Rn. If the function f : U → R is differentiable, then the differential of f is the (Fréchet) derivative of f. Thus ∇f is a function from U to the space Rn such that

where · is the dot product.
As a consequence, the usual properties of the derivative hold for the gradient:
Linearity[edit]
The gradient is linear in the sense that if f and g are two real-valued functions differentiable at the point a ∈ Rn, and α and β are two constants, then αf + βg is differentiable at a, and moreover

Product rule[edit]
If f and g are real-valued functions differentiable at a point a ∈ Rn, then the product rule asserts that the product fg is differentiable at a, and

Chain rule[edit]
Suppose that f : A → R is a real-valued function defined on a subset A of Rn, and that f is differentiable at a point a. There are two forms of the chain rule applying to the gradient. First, suppose that the function g is a parametric curve; that is, a function g : I → Rn maps a subset I ⊂ R into Rn. If g is differentiable at a point c ∈ I such that g(c) = a, then

where ∘ is the composition operator: ( f ∘ g)(x) = f(g(x)).
More generally, if instead I ⊂ Rk, then the following holds:

where (Dg)T denotes the transpose Jacobian matrix.
For the second form of the chain rule, suppose that h : I → R is a real valued function on a subset I of R, and that h is differentiable at the point f(a) ∈ I. Then

Further properties and applications[edit]
Level sets[edit]
A level surface, or isosurface, is the set of all points where some function has a given value.
If f is differentiable, then the dot product (∇f )x ⋅ v of the gradient at a point x with a vector v gives the directional derivative of f at x in the direction v. It follows that in this case the gradient of f is orthogonal to the level sets of f. For example, a level surface in three-dimensional space is defined by an equation of the form F(x, y, z) = c. The gradient of F is then normal to the surface.
More generally, any embedded hypersurface in a Riemannian manifold can be cut out by an equation of the form F(P) = 0 such that dF is nowhere zero. The gradient of F is then normal to the hypersurface.
Similarly, an affine algebraic hypersurface may be defined by an equation F(x1, ..., xn) = 0, where F is a polynomial. The gradient of F is zero at a singular point of the hypersurface (this is the definition of a singular point). At a non-singular point, it is a nonzero normal vector.
Conservative vector fields and the gradient theorem[edit]
The gradient of a function is called a gradient field. A (continuous) gradient field is always a conservative vector field: its line integral along any path depends only on the endpoints of the path, and can be evaluated by the gradient theorem (the fundamental theorem of calculus for line integrals). Conversely, a (continuous) conservative vector field is always the gradient of a function.
Generalizations[edit]
Gradient of a vector[edit]
Since the total derivative of a vector field is a linear mapping from vectors to vectors, it is a tensor quantity.
In rectangular coordinates, the gradient of a vector field f = ( f1, f2, f3) is defined by:

(where the Einstein summation notation is used and the tensor product of the vectors ei and ek is a dyadic tensor of type (2,0)). Overall, this expression equals the transpose of the Jacobian matrix:

In curvilinear coordinates, or more generally on a curved manifold, the gradient involves Christoffel symbols:

where gjk are the components of the inverse metric tensor and the ei are the coordinate basis vectors.
Expressed more invariantly, the gradient of a vector field f can be defined by the Levi-Civita connection and metric tensor:[2]

where ∇c is the connection.
Riemannian manifolds[edit]
For any smooth function f on a Riemannian manifold (M, g), the gradient of f is the vector field ∇f such that for any vector field X,

i.e.,

where gx( , ) denotes the inner product of tangent vectors at x defined by the metric g and ∂X f is the function that takes any point x ∈ M to the directional derivative of f in the direction X, evaluated at x. In other words, in a coordinate chart φ from an open subset of M to an open subset of Rn, (∂X f )(x) is given by:

where Xj denotes the jth component of X in this coordinate chart.
So, the local form of the gradient takes the form:

Generalizing the case M = Rn, the gradient of a function is related to its exterior derivative, since

More precisely, the gradient ∇f is the vector field associated to the differential 1-form df using the musical isomorphism

(called "sharp") defined by the metric g. The relation between the exterior derivative and the gradient of a function on Rn is a special case of this in which the metric is the flat metric given by the dot product.
See also[edit]
References[edit]
- ^ a b Schey 1992, pp. 139–142.
- ^ Dubrovin, Fomenko & Novikov 1991, pp. 348–349.
Further reading[edit]
- Korn, Theresa M.; Korn, Granino Arthur (2000). Mathematical Handbook for Scientists and Engineers: Definitions, Theorems, and Formulas for Reference and Review. Dover Publications. pp. 157–160. ISBN 0-486-41147-8. OCLC 43864234.
- Schey, H. M. (1992). Div, Grad, Curl, and All That (2nd ed.). W. W. Norton. ISBN 0-393-96251-2. OCLC 25048561.
- Dubrovin, B. A.; Fomenko, A. T.; Novikov, S. P. (1991). Modern Geometry—Methods and Applications: Part I: The Geometry of Surfaces, Transformation Groups, and Fields. Graduate Texts in Mathematics (2nd ed.). Springer. ISBN 978-0-387-97663-1.
External links[edit]
| Look up gradient in Wiktionary, the free dictionary. |
- "Gradient". Khan Academy.
- Kuptsov, L.P. (2001) [1994], "Gradient", in Hazewinkel, Michiel, Encyclopedia of Mathematics, Springer Science+Business Media B.V. / Kluwer Academic Publishers, ISBN 978-1-55608-010-4.
- Weisstein, Eric W. "Gradient". MathWorld.