JIS X 0201
 JIS X 0201 8-bit code page | |
| MIME / IANA | 8-bit: JIS_X02017-bit Roman: JIS_C6220-1969-ro7-bit Kana: JIS_C6220-1969-jp |
|---|---|
| Alias(es) | JIS C 6220 8-bit: csHalfWidthKatakana Roman: ISO646-JP, iso-ir-14 Kana: iso-ir-13, x0201-7 |
| Language(s) | Japanese (basic support), English |
| Standard | JIS X 0201:1969 |
| Classification | ISO 646, Extended ISO 646 |
| Preceded by | Wabun code |
| Succeeded by | Shift JIS |
JIS X 0201, a Japanese Industrial Standard developed in 1969 (then called JIS C 6220 until the JIS category reform), was the first Japanese electronic character set to become widely used. It is either 7-bit encoding or 8-bit encoding, although 8-bit encoding is dominant for modern use. The full name of this standard is 7-bit and 8-bit coded character sets for information interchange (7ビット及び8ビットの情報交換用符号化文字集合).
The first 96 codes comprise an ISO 646 variant, mostly following ASCII with some differences, while the second 96 character codes represent the phonetic Japanese katakana signs. Since the encoding does not provide any way to express hiragana or kanji, it is only capable of expressing simplified written Japanese. Nevertheless, it is possible to express, at least phonetically, the full range of sounds in the language. In the 1980s, this was acceptable for media such as text mode computer terminals, telegrams, receipts or other electronically handled data.
JIS X 0201 was supplanted by subsequent encodings such as Shift JIS (which combines this standard and JIS X 0208) and later Unicode.
Contents
Implementation details[edit]


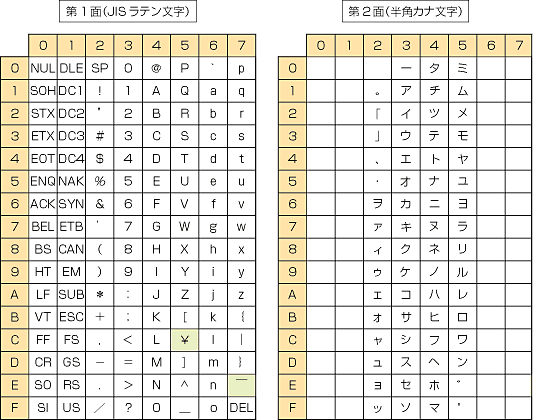
The first 96 codes in JIS comprise a Japanese variant of ISO 646, or ASCII with backslash (\) and tilde (~) replaced by yen (¥) and overline (‾),[1] while the second 96 codes consist mainly of katakana. Control characters are specified in JIS X 0211.
In the 7-bit format, the shift out control character (0x0E) switches to the Kana set and shift in (0x0F) switches to the Roman set.[2][3] In the 8-bit format, given in the chart below, bytes with the most significant bit set (i.e. 0x80–0xFF) are used for the Kana set and bytes with it unset (i.e. 0x00–0x7F) are used otherwise.
The substitution of the yen symbol for backslash can make paths on DOS and Windows-based computers with Japanese support display strangely, like "C:¥Program Files¥", for example.[4] Another similar problem is C programming language's control characters of string literals, like printf("Hello, world.¥n");.
Codepage layout[edit]
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0_ 0 |
||||||||||||||||
| 1_ 16 |
||||||||||||||||
| 2_ 32 |
SP 0020 |
! 0021 |
" 0022 |
# 0023 |
$ 0024 |
% 0025 |
& 0026 |
' 0027 |
( 0028 |
) 0029 |
* 002A |
+ 002B |
, 002C |
- 002D |
. 002E |
/ 002F |
| 3_ 48 |
0 0030 |
1 0031 |
2 0032 |
3 0033 |
4 0034 |
5 0035 |
6 0036 |
7 0037 |
8 0038 |
9 0039 |
: 003A |
; 003B |
< 003C |
= 003D |
> 003E |
? 003F |
| 4_ 64 |
@ 0040 |
A 0041 |
B 0042 |
C 0043 |
D 0044 |
E 0045 |
F 0046 |
G 0047 |
H 0048 |
I 0049 |
J 004A |
K 004B |
L 004C |
M 004D |
N 004E |
O 004F |
| 5_ 80 |
P 0050 |
Q 0051 |
R 0052 |
S 0053 |
T 0054 |
U 0055 |
V 0056 |
W 0057 |
X 0058 |
Y 0059 |
Z 005A |
[ 005B |
¥ 00A5 |
] 005D |
^ 005E |
_ 005F |
| 6_ 96 |
` 0060 |
a 0061 |
b 0062 |
c 0063 |
d 0064 |
e 0065 |
f 0066 |
g 0067 |
h 0068 |
i 0069 |
j 006A |
k 006B |
l 006C |
m 006D |
n 006E |
o 006F |
| 7_ 112 |
p 0070 |
q 0071 |
r 0072 |
s 0073 |
t 0074 |
u 0075 |
v 0076 |
w 0077 |
x 0078 |
y 0079 |
z 007A |
{ 007B |
| 007C |
} 007D |
‾ 203E |
|
| 8_ 128 |
||||||||||||||||
| 9_ 144 |
||||||||||||||||
| A_ 160 |
。 FF61 |
「 FF62 |
」 FF63 |
、 FF64 |
・ FF65 |
ヲ FF66 |
ァ FF67 |
ィ FF68 |
ゥ FF69 |
ェ FF6A |
ォ FF6B |
ャ FF6C |
ュ FF6D |
ョ FF6E |
ッ FF6F | |
| B_ 176 |
ー FF70 |
ア FF71 |
イ FF72 |
ウ FF73 |
エ FF74 |
オ FF75 |
カ FF76 |
キ FF77 |
ク FF78 |
ケ FF79 |
コ FF7A |
サ FF7B |
シ FF7C |
ス FF7D |
セ FF7E |
ソ FF7F |
| C_ 192 |
タ FF80 |
チ FF81 |
ツ FF82 |
テ FF83 |
ト FF84 |
ナ FF85 |
ニ FF86 |
ヌ FF87 |
ネ FF88 |
ノ FF89 |
ハ FF8A |
ヒ FF8B |
フ FF8C |
ヘ FF8D |
ホ FF8E |
マ FF8F |
| D_ 208 |
ミ FF90 |
ム FF91 |
メ FF92 |
モ FF93 |
ヤ FF94 |
ユ FF95 |
ヨ FF96 |
ラ FF97 |
リ FF98 |
ル FF99 |
レ FF9A |
ロ FF9B |
ワ FF9C |
ン FF9D |
゙ FF9E |
゚ FF9F |
| E_ 224 |
||||||||||||||||
| F_ 240 |
Variants and extensions[edit]
Shift JIS[edit]
IBM's implementations[edit]
Code page 897 is IBM's implementation of the 8-bit form of JIS X 0201. It includes several additional graphical characters in the C0 control characters area, and the code points in question may be used as control characters or graphical characters depending on the context,[5] similarly in concept to OEM-US, but with different graphical characters. The C0 rows are shown below.
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0_ 0 |
NUL 0000 |
╔ 2554 |
╗ 2557 |
╚ 255A |
╝ 255D |
║ 2551 |
═ 2550 |
↓ FFEC |
BS 0008 |
○ FFEE |
LF 000A |
〿 303F |
FF 000C |
CR 000D |
■ FFED |
☼ 263C |
| 1_ 16 |
╬ 256C |
DC1 0011 |
↕ 2195 |
DC3 0013 |
▓ 2593 |
╩ 2569 |
╦ 2566 |
╣ 2563 |
CAN 0018 |
╠ 2560 |
░/FS 2591/001C |
↵ 21B5 |
↑/DEL FFEA/007F |
│ FFE8 |
→ FFEB |
← FFE9 |
IBM also implements the 7-bit Roman set of JIS X 0201 as Code page 895[11] and the 7-bit Kana set as Code page 896 for use as ISO 2022 or EUC-JP code-sets. Code page 896, in addition to standard JIS X 0201 assignments, defines five additional assignments, shown below.[12] Although use of these extended characters is not permitted by the associated CCSID 896,[13] they are permitted by the alternative CCSID 4992.[14]
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 6_ 96 |
¢ 00A2 |
£ 00A3 |
¬ 00AC |
\ 005C |
~ 007E |
IBM's Code page 1041 is an extended version of Code page 897, encoding these five IBM extended[15] characters in alternative locations which are compatible with Shift JIS (respectively 0x80, 0xA0, 0xFD, 0xFE and 0xFF).[16]
IBM's Code page 903 is encoded for use as the single byte component of certain simplified Chinese character encodings.[17] Despite this, it follows ISO 646-JP / the Roman half of JIS X 0201, in that it replaces the ASCII backslash 0x5C (rather than the ASCII dollar sign 0x24 as in GB 1988 / ISO 646-CN) with the yen/yuan sign. It also uses the same C0 replacement graphics as code page 897.[18] It is closely related to Code page 904, which is encoded for use as the single byte component of certain traditional Chinese character encodings,[19][20] and uses the same C0 replacement graphics, but follows ASCII.[21]
Others[edit]


References[edit]
- ^ "3.1.1 Details of Problems". Problems and Solutions for Unicode and User/Vendor Defined Characters. The Open Group Japan. Archived from the original on 1999-02-03.
- ^ ISO-IR 013: The Japanese KATAKANA graphic set of characters (PDF), Information Technology Standards Commission of Japan
- ^ ISO-IR 014: The Japanese Roman graphic set of characters (PDF), Information Technology Standards Commission of Japan
- ^ Kaplan, Michael S. (2005-09-17). "When is a backslash not a backslash?".
- ^ "Code page identifiers - CP 00897". IBM Globalization. IBM. Archived from the original on 2016-03-17.
- ^ "CP00897.pdf" (PDF). IBM. Archived from the original on 2019-01-12.
- ^ "CP00897.txt". IBM. Archived from the original on 2019-01-12.
- ^ "Converter Explorer - ibm-943_P130-1999". ICU Demonstration. International Components for Unicode.
- ^ "Coded character set identifiers - CCSID 943". IBM Globalization. IBM. Archived from the original on 2016-03-15.
- ^ Graphics are listed per CP00897.pdf and CP00897.txt provided by IBM.[6][7] Controls are listed, in absence of graphical function or where they differ from ASCII, per the ibm-943_P130-1999 codec provided by IBM to International Components for Unicode[8] (IBM-943 is a Code page 897 superset).[9] SUB is assigned to 0x7F.
- ^ "CP00895.pdf" (PDF). IBM. Archived from the original on 2017-12-07.
- ^ a b "CP00896.pdf" (PDF). IBM. Archived from the original on 2019-01-12.
- ^ "Coded character set identifiers - CCSID 896". IBM Globalization. IBM. Archived from the original on 2016-03-26.
- ^ "Coded character set identifiers - CCSID 4992". IBM Globalization. IBM. Archived from the original on 2016-03-27.
- ^ "11.2 - IBM Extended SBCS Set". IBM Japanese Graphic Character Set for Extended UNIX Code (EUC) (PDF). IBM. p. 315. Archived from the original on 2019-01-12.
- ^ "CP01041.pdf" (PDF). IBM. Archived from the original on 2019-01-12.
- ^ "Code page identifiers - CP 903". IBM Globalization. IBM. Archived from the original on 2016-03-17.
- ^ "CP00903.pdf" (PDF). IBM. Archived from the original on 2019-01-12.
- ^ "Code page identifiers - CP 904". IBM Globalization. IBM.[permanent dead link]
- ^ "Coded character set identifiers - CCSID 904". IBM Globalization. IBM. Archived from the original on 2016-03-27.
- ^ "CP00904.pdf" (PDF). IBM. Archived from the original on 2019-01-12.
{kind=link}