PostBQP
In computational complexity theory, PostBQP is a complexity class consisting of all of the computational problems solvable in polynomial time on a quantum Turing machine with postselection and bounded error (in the sense that the algorithm is correct at least 2/3 of the time on all inputs).
Postselection is not considered to be a feature that a realistic computer (even a quantum one) would possess, but nevertheless postselecting machines are interesting from a theoretical perspective.
Removing either one of the two main features (quantumness, postselection) from PostBQP gives the following two complexity classes, both of which are subsets of PostBQP:
- BQP is the same as PostBQP except without postselection
- BPPpath is the same as PostBPP except that instead of quantum, the algorithm is a classical randomized algorithm (with postselection)[1]
The addition of postselection seems to make quantum Turing machines much more powerful: Scott Aaronson proved[2][3] PostBQP is equal to PP, a class which is believed to be relatively powerful, whereas BQP is not known even to contain the seemingly smaller class NP. Using similar techniques, Aaronson also proved that small changes to the laws of quantum computing would have significant effects. As specific examples, under either of the two following changes, the "new" version of BQP would equal PP:
- if we broadened the definition of 'quantum gate' to include not just unitary operations but linear operations, or
- if the probability of measuring a basis state was proportional to instead of for any even integer p > 2.



Basic properties[edit]
In order to describe some of the properties of PostBQP we fix a formal way of describing quantum postselection. Define a quantum algorithm to be a family of quantum circuits (specifically, a uniform circuit family). We designate one qubit as the postselection qubit P and another as the output qubit Q. Then PostBQP is defined by postselecting upon the event that the postselection qubit is |1>. Explicitly, a language L is in PostBQP if there is a quantum algorithm A so that after running A on input x and measuring the two qubits P and Q,
- P = 1 with nonzero probability
- if the input x is in L then Pr[Q = 1|P = 1] ≥ 2/3
- if the input x is not in L then Pr[Q = 0|P = 1] ≥ 2/3.
One can show that allowing a single postselection step at the end of the algorithm (as described above) or allowing intermediate postselection steps during the algorithm are equivalent.[2][4]
Here are three basic properties of PostBQP (which also hold for BQP via similar proofs):
1. PostBQP is closed under complement. Given a language L in PostBQP and a corresponding deciding circuit family, create a new circuit family by flipping the output qubit after measurement, then the new circuit family proves the complement of L is in PostBQP.
2. You can do probability amplification in PostBQP. The definition of PostBQP is not changed if we replace the 2/3 value in its definition by any other constant strictly between 1/2 and 1. As an example, given a PostBQP algorithm A with success probability 2/3, we can construct another algorithm which runs three independent copies of A, outputs a postselection bit equal to the conjunction of the three "inner" ones, and outputs an output bit equal to the majority of the three "inner" ones; the new algorithm will be correct with conditional probability , greater than the original 2/3.

3. PostBQP is closed under intersection. Suppose we have PostBQP circuit families for two languages L1 and L2, with respective postselection qubits and output qubits P1, P2, Q1, Q2. We may assume by probability amplification that both circuit families have success probability at least 5/6. Then we create a composite algorithm where the circuits for L1 and L2 are run independently, and we set P to the conjunction of P1 and P2, and Q to the conjunction of Q1 and Q2. It is not hard to see by a union bound that this composite algorithm correctly decides membership in with (conditional) probability at least 2/3.

More generally, combinations of these ideas show that PostBQP is closed under union and BQP truth-table reductions.
PostBQP = PP[edit]
Scott Aaronson showed[5] that the complexity classes PostBQP (postselected bounded error quantum polynomial time) and PP (probabilistic polynomial time) are equal. The result was significant because this quantum computation reformulation of PP gave new insight and simpler proofs of properties of PP.
The usual definition of a PostBQP circuit family is one with two outbit qubits P (postselection) and Q (output) with a single measurement of P and Q at the end such that the probability of measuring P = 1 has nonzero probability, the conditional probability Pr[Q = 1|P = 1] ≥ 2/3 if the input x is in the language, and Pr[Q = 0|P = 1] ≥ 2/3 if the input x is not in the language. For technical reasons we tweak the definition of PostBQP as follows: we require that Pr[P = 1] ≥ 2−nc for some constant c depending on the circuit family. Note this choice does not affect the basic properties of PostBQP, and also it can be shown that any computation consisting of typical gates (e.g. Hadamard, Toffoli) has this property whenever Pr[P = 1] > 0.
Proving PostBQP ⊆ PP[edit]
Suppose we are given a PostBQP family of circuits to decide a language L. We assume without loss of generality (e.g. see the inessential properties of quantum computers) that all gates have transition matrices that are represented with real numbers, at the expense of adding one more qubit.
Let Ψ denote the final quantum state of the circuit before the postselecting measurement is made. The overall goal of the proof is to construct a PP algorithm to decide L. More specifically it suffices to have L correctly compare the squared amplitude of Ψ in the states with Q = 1, P = 1 to the squared amplitude of Ψ in the states with Q = 0, P = 1 to determine which is bigger. The key insight is that the comparison of these amplitudes can be transformed into comparing the acceptance probability of a PP machine with 1/2.
Matrix view of PostBQP algorithms[edit]
Let n denote the input size, B = B(n) denote the total number of qubits in the circuit (inputs, ancillary, output and postselection qubits), and G = G(n) denote the total number of gates. Represent the ith gate by its transition matrix Ai (a real unitary matrix) and let the initial state be |x> (padded with zeroes). Then . Define S1 (resp. S0) to be the set of basis states corresponding to P = 1, Q = 1 (resp. P = 1, Q = 0) and define the probabilities


![\pi _{1}:={\text{Pr}}[P=1,Q=1]=\sum _{{\omega \in S_{1}}}\Psi _{\omega }^{2}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2d562f414599d8a01b10b02cfba795b0f87cd358)
![\pi _{0}:={\text{Pr}}[P=1,Q=0]=\sum _{{\omega \in S_{0}}}\Psi _{\omega }^{2}.](https://wikimedia.org/api/rest_v1/media/math/render/svg/81f94423565b0f388ac58519d053b84bbb726f9b)
The definition of PostBQP ensures that either or according to whether x is in L or not.


Our PP machine will compare and . In order to do this, we expand the definition of matrix multiplication:



where the sum is taken over all lists of G basis vectors . Now and can be expressed as a sum of pairwise products of these terms. Intuitively, we want to design a machine whose acceptance probability is something like , since then would imply that the acceptance probability is , while would imply that the acceptance probability is .






Technicality: we may assume entries of the transition matrices Ai are rationals with denominator 2f(n) for some polynomial f(n).[edit]
The definition of PostBQP tells us that if x is in L, and that otherwise . Let us replace all entries of A by the nearest fraction with denominator for a large polynomial that we presently describe. What will be used later is that the new π values satisfy if x is in L, and if x is not in L. Using the earlier technical assumption and by analyzing how the 1-norm of the computational state changes, this is seen to be satisfied if thus clearly there is a large enough f that is polynomial in n.







Constructing the PP machine[edit]
Now we provide the detailed implementation of our PP machine. Let α denote the sequence and define the shorthand notation

- ,

then

We define our PP machine to
- pick a basis state ω uniformly at random
- if then STOP and accept with probability 1/2, reject with probability 1/2
- pick two sequences of G basis states uniformly at random
- compute (which is a fraction with denominator such that )
- if then accept with probability and reject with probability (which takes at most coin flips)
- otherwise (then ) accept with probability and reject with probability (which again takes at most coin flips)










Then it is straightforward to compute that this machine accepts with probability so this is a PP machine for the language L, as needed.

Proving PP ⊆ PostBQP[edit]
Suppose we have a PP machine with time complexity T:=T(n) on input x of length n := |x|. Thus the machine flips a coin at most T times during the computation. We can thus view the machine as a deterministic function f (implemented, e.g. by a classical circuit) which takes two inputs (x, r) where r, a binary string of length T, represents the results of the random coin flips that are performed by the computation, and the output of f is 1 (accept) or 0 (reject). The definition of PP tells us that

Thus, we want a PostBQP algorithm that can determine whether the above statement is true.
Define s to be the number of random strings which lead to acceptance,

and so is the number of rejected strings. It is straightforward to argue that without loss of generality, ; for details, see a similar without loss of generality assumption in the proof that PP is closed under complementation.


Aaronson's algorithm[edit]
Aaronson's algorithm for solving this problem is as follows. For simplicity, we will write all quantum states as unnormalized. First, we prepare the state . Second, we apply Hadamard gates to the first register (each of the first T qubits), measure the first register and postselect on it being the all-zero string. It is easy to verify that this leaves the last register (the last qubit) in the residual state


Where H denotes the Hadamard gate, we compute the state
- .

Where are positive real numbers to be chosen later with , we compute the state and measure the second qubit, postselecting on its value being equal to 1, which leaves the first qubit in a residual state depending on which we denote




- .

Visualizing the possible states of a qubit as a circle, we see that if , (i.e. if ) then lies in the open quadrant while if , (i.e. if ) then lies in the open quadrant . In fact for any fixed x (and its corresponding s), as we vary the ratio in , note that the image of is precisely the corresponding open quadrant. In the rest of the proof, we make precise the idea that we can distinguish between these two quadrants.







Analysis[edit]
Let , which is the center of , and let be orthogonal to . Any qubit in , when measured in the basis , gives the value less than 1/2 of the time. On the other hand, if and we had picked then measuring in the basis would give the value all of the time. Since we don't know s we also don't know the precise value of r*, but we can try several (polynomially many) different values for in hopes of getting one that is "near" r*.







Specifically, note and let us successively set to every value of the form for . Then elementary calculations show that for one of these values of i, the probability that the measurement of in the basis yields is at least





Overall, the PostBQP algorithm is as follows. Let k be any constant strictly between 1/2 and . We do the following experiment for each : construct and measure in the basis a total of times where C is a constant. If the proportion of measurements is greater than k, then reject. If we don't reject for any i, accept. Chernoff bounds then show that for a sufficiently large universal constant C, we correctly classify x with probability at least 2/3.


Note that this algorithm satisfies the technical assumption that the overall postselection probability is not too small: each individual measurement of has postselection probability and so the overall probability is .


Implications[edit]
References[edit]
- ^ Y. Han and Hemaspaandra, L. and Thierauf, T. (1997). "Threshold computation and cryptographic security". SIAM Journal on Computing. 26: 59–78. CiteSeerX 10.1.1.23.510. doi:10.1137/S0097539792240467.CS1 maint: Multiple names: authors list (link)
- ^ a b Aaronson, Scott (2005). "Quantum computing, postselection, and probabilistic polynomial-time". Proceedings of the Royal Society A. 461 (2063): 3473–3482. arXiv:quant-ph/0412187. Bibcode:2005RSPSA.461.3473A. doi:10.1098/rspa.2005.1546.. Preprint available at [1]
- ^ Aaronson, Scott (2004-01-11). "Complexity Class of the Week: PP". Computational Complexity Weblog. Retrieved 2008-05-02.
- ^ Ethan Bernstein & Umesh Vazirani (1997). "Quantum Complexity Theory". SIAM Journal on Computing. 26 (5): 11–20. CiteSeerX 10.1.1.144.7852. doi:10.1137/s0097539796300921.
- ^ Aaronson, Scott (2005). "Quantum computing, postselection, and probabilistic polynomial-time". Proceedings of the Royal Society A. 461 (2063): 3473–3482. arXiv:quant-ph/0412187. Bibcode:2005RSPSA.461.3473A. doi:10.1098/rspa.2005.1546.
| General | 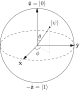 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Quantum communication | |||||||||
| Quantum algorithms | |||||||||
| Quantum complexity theory | |||||||||
| Quantum computing models | |||||||||
| Quantum error correction | |||||||||
| Physical implementations |
| ||||||||
| Software | |||||||||